Week of 3/7
Woah, hello there pals! This week (or these two weeks, I suppose) have been quite interesting. I've settled into my new home (after staying for what felt like weeks at my aunt's apartment), and after throwing some stuff out, I finally found space in my room (and in the house). But no matter on that. Let's talk about the progress I've made so far with my super epic research. While I was expanding my knowledge base of Q-learning, I discovered DQN. DQN is also known as Deep Q Learning. It's kind of like Q-learning but it uses neural networks, hence the name "deep". I think that it's infinitely better than regular Q-learning, since Q-learning takes up way too much memory in its quest for game states and specific game state/action pairs. Robert says that he's looking into a deep Q-learning specific application for our dots and boxes game, but that's the extent of our progress on it so far.
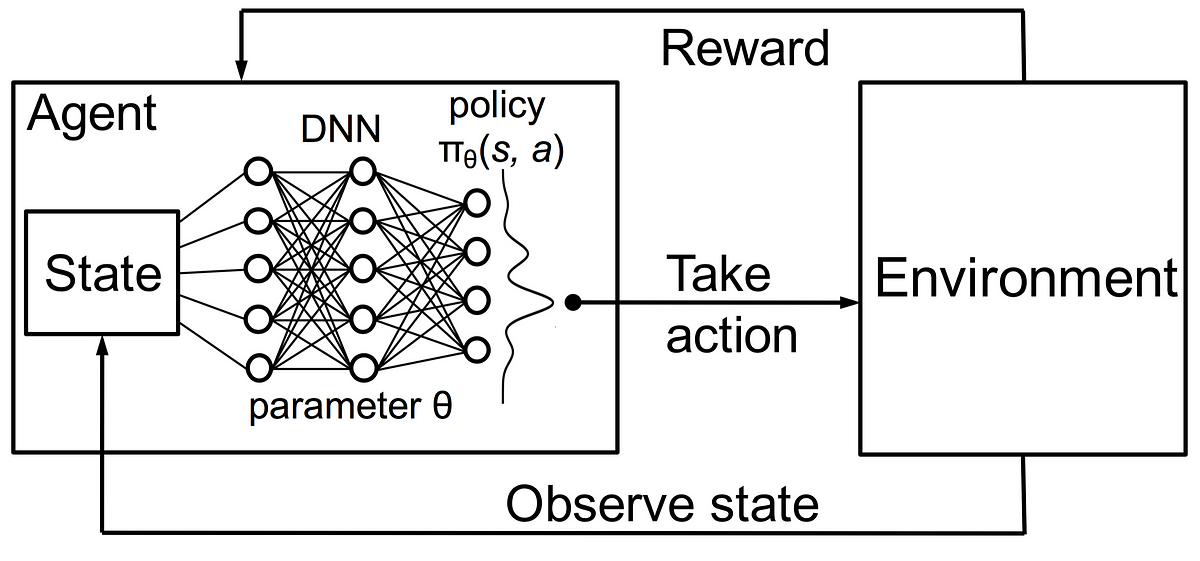

Deep Q- Learning.
Regular Q-learning.
Notice how deep Q-learning uses neural networks to assign weights and evaluate rewards. On the other hand, normal Q-learning uses Q-tables and reward values (of which its parameters are set by the user). Notice how deep Q-learning just seems so much more "big-brained". The next step is to learn how to actually implement a neural network and how to format the code to run with the game itself.
We also met with our CalTech professors on Thursday. Well, to be more accurate, we met with the grad students since Dr. (or Professor? I'm not sure which one to call him) Hassibi is busy with his smart person work. We discussed our idea of immediately finding solutions to fix our current dots-and-boxes game and our goal of finding a reinforcement learning algorithm to implement onto the game. As always, this was quickly shot down and some new ideas were pushed forth. Because we definitely want an end product, the grad students suggested that we look into supervised learning for games like tic-tac-toe. Tic-tac-toe is already a solved game, so it shouldn't be too hard. Additionally, we would try to choose an unsupervised learning method to play tic-tac-toe, and another for our dots-and-boxes game. This way, we can learn how to create the game that we want to while also ensuring for a fact that we will have an end product to present by the end of the semester.
This guy made a tic-tac-toe neural network in under an hour. He used javascript though.
Our biggest struggle was choosing a reinforcement learning algorithm and finding a dataset for tic-tac-toe that would actually work on Python (and would make enough sense for us to format it). A lot of the websites we looked at formatted all the data very weirdly (including some websites only presenting end game game states, which I didn't think was particularly helpful for our case). We pulled through, since Will was super passionate about his Monte Carlo Search Tree reinforcement learning algorithm and found someone's code that actually played tic-tac-toe with that learning algorithm. It's pretty cool, and I can't wait for part two of his explanation of how Monte Carlo even works in the first place.
A Crash Course I found helpful
What I do know right now about the Monte Carlo Search Tree algorithm is that it's the same algorithm that's employed by Google's AlphaGo game. That's highly impressive. The normal tree search uses randomized "roller" assignments to determine the weights and values of each action given a game state, but I did hear him mention that it can be simplified using a neural network to automatically and efficiently determine the weights and rewards for each game state and action pair. I'm excited to explore that further and to learn some bit more. Cheers for more progress!
Comments
Post a Comment