Week of 10/1
This week we learned about decision trees and how it works in regards to dataset organization and future prediction. While it was kind of tough, we first tried to understand what decision trees were. Decisions trees are a form of supervised learning that tries to train itself using existing datasets and predict classifications of certain subjects based on the data given to it. We learned that decision trees generally used generally binary splitting choices to actually find ways to sort and categorize data. Using this technique, it is possible to predict future inputs of data and see whether or not a certain data point entered would be classified in certain categories.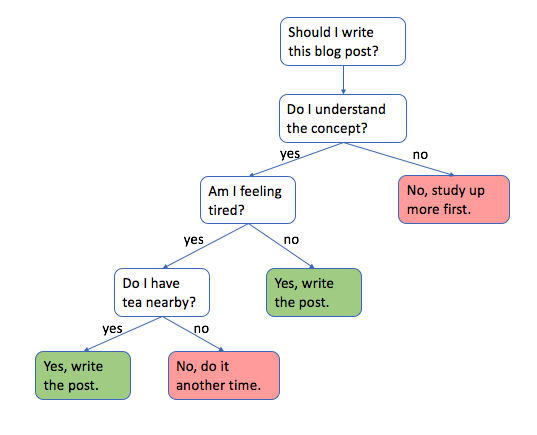
This guy was pretty good at explaining to be the basics of decision trees:
The team and I wanted to figure out some of the nuances of decision tree learning, and so we went on a journey of our endless pursuit of knowledge. I, for example, wanted to figure out how the computer was able to decide on how to split and evaluate the different splitting options. After some research and a lot of discussion and arguments, I think I can kind of understand why and how different "classes" are split into "nodes". For example, if a certain dataset were to only split binarily and only had two total classification orders within it to be split to, then the number of splits it could make would just be n-1 if n was the number of classes it had to be split to. If there are multiple classification orders, then you evaluate the total amount of splits it can make as 2^(n-1)-1 given a particular n set of categories within the set of data that needs to be split. However, this equation only applies to each individual layer of splitting on a decision tree, so limitations do apply. n cannot be too large of a number, otherwise that would probably break the computer.
We worked with the iris data set and the Titanic data set. They were both pretty cool and gave me a chance to work with the code and figure out what each line of code did to modify and use the data sets.

This is us learning decision trees. Fun time. Aston not included in the picture.
On the concept map, I specifically focused on datasets. Datasets, specifically to decision trees, are pretty useful to actually make decision trees to do anything. Decision tree programming requires a dataset to be readily available for its values to be manipulated and learned. I learned how to organize datasets effectively and be able to format them into computer-friendly formats. While I'm not particularly good at it, I think the future research projects and stuff will be able to give me a chance to practice these skills.
We also worked on paper airplanes- while the gym's really stuffy, we still get stuff done. This time we tested how the material of the planes would affect the flight time of the planes. Lo and behold, the cardstock plane flew the longest time. I think that even though it's really heavy, the fact that it was actually able to stay together and not collapse on itself (like the newspaper airplane) really helped it leaps and bounds in flying further. We didn't record that time, but just for fun, Will was able to throw it across the gym with it flying in a straight line. That was pretty impressive.
Here is my linear regression video since I really haven't found the time to do my decision tree one yet:
Comments
Post a Comment